 Parea
PareaTest and Evaluate your AI systems
From experiment tracking, to observability, to human annotation,
Parea helps teams confidently ship LLM apps to production.

TRUSTED BY TEAMS AT



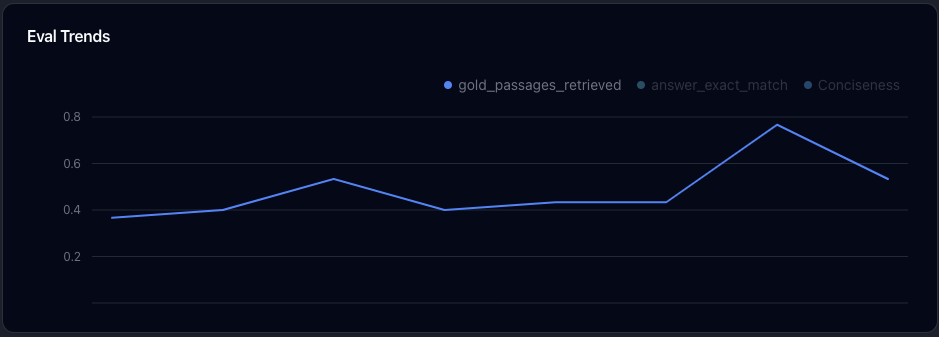
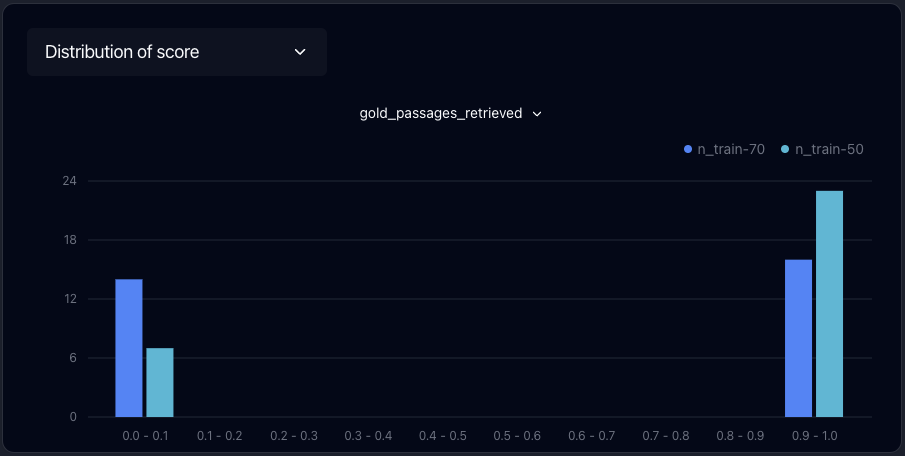
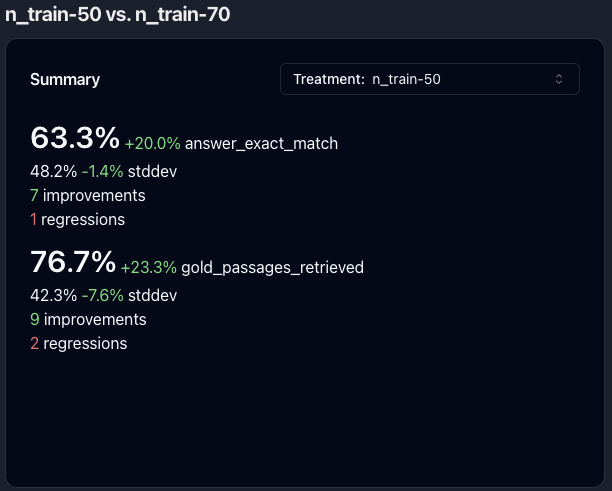
Evaluation
Test, and track performance over time. Debug failures. Answer questions like “which samples regressed when I made a change?”, and “does upgrading to this new model improve performance?”
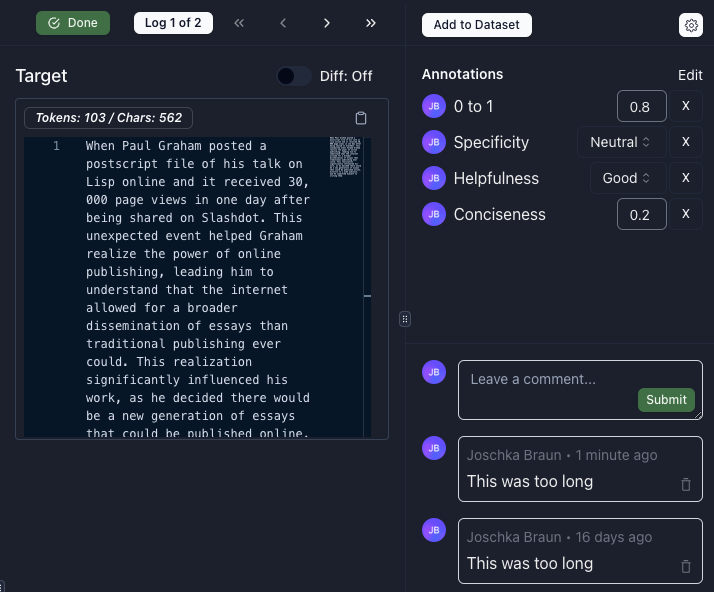
Human Review
Collect human feedback from end users, subject matter experts, and product teams. Comment on, annotate and label logs for Q&A and fine-tuning.
Prompt Playground & Deployment
Tinker with multiple prompts on samples, test them on large datasets, and deploy the good ones into production.
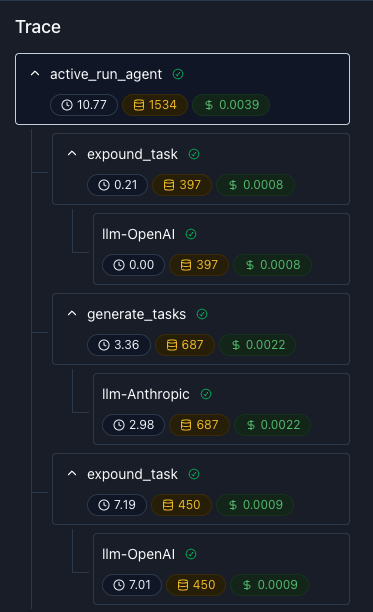
Observability
Log production and staging data. Debug issues, run online evals, and capture user feedback. Track cost, latency, and quality in one place.
Datasets
Incorporate logs from staging & production into test datasets and use them to fine-tune models.
Simple Python & JavaScript SDKs
from openai import OpenAI
from parea import Parea, trace
client = OpenAI()
p = Parea(api_key="PAREA_API_KEY")
p.wrap_openai_client(client) # auto-trace LLM calls
# trace and evaluate any steps
@trace(eval_funcs=[...])
def func(...):
...
# run tests on datasets
p.experiment(...)import OpenAI from "openai";
import { Parea, patchOpenAI, trace } from "parea-ai";
const openai = new OpenAI();
const p = new Parea(process.env.PAREA_API_KEY);
patchOpenAI(openai); // auto-trace LLM calls
const func = trace( // trace step
'funcName', origFunc,
{ evalFuncs: [...], }, // evaluate step
);
// run tests on datasets
p.experiment(...)Native integrations to major LLM providers & frameworks
Pricing for teams of all sizes
Get started on the Builder plan for free. No credit card required.
Free
- All platform features
- Max. 2 team members
- 3k logs / month (1 mon retention)
- 10 deployed prompts
- Discord community
Team
- 3 members ($50 / month per add'l. member up to 20)
- 100k logs / month incl. ($0.001 / extra log)
- 3 month data retention, (6/12 mon upgrade)
- Unlimited projects
- 100 deployed prompts
- Private Slack channel
Enterprise
- On-prem/self-hosting
- Support SLAs
- Unlimited logs
- Unlimited deployed prompts
- SSO enforcement and custom roles
- Additional security and compliance features
AI Consulting
- Rapid Prototyping & Research
- Building domain-specific evals
- Optimizing RAG pipelines
- Upskilling your team on LLMs